
First, I divided the data into two parts. The first part is “training” which I will be building the model with. The second part is “test” which I will use to test the model I already made.

Using these two data sets, my data contains 70% of the original observations and the test data contains 30%.

Next I will build and run the model that predicts wins using home runs, walks, and RBI’s.
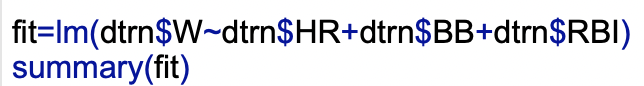
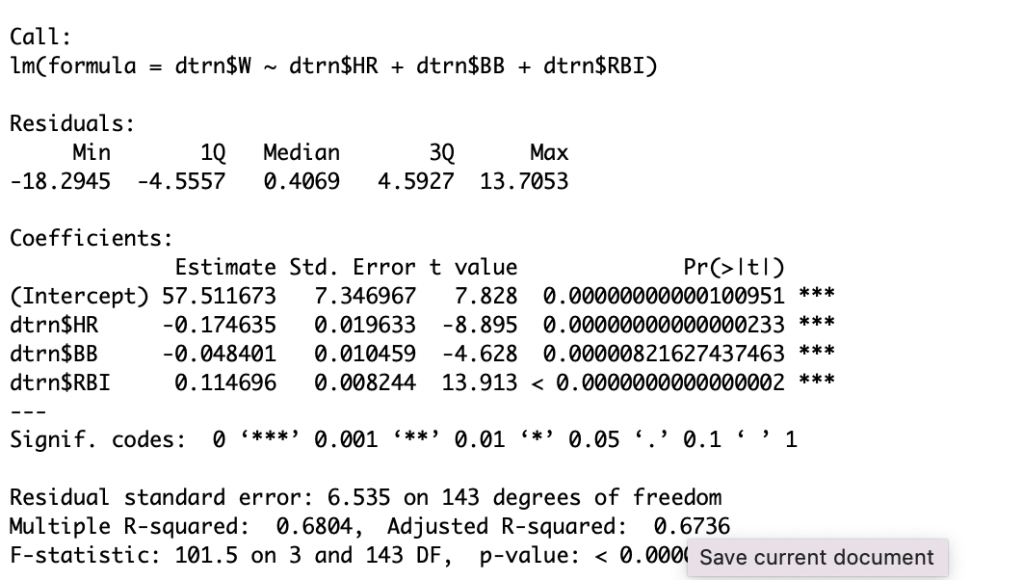
Using this, its model equation is Wins= 57.51-.17*HR-.05*BB+.11*RBI
Now I will make predictions for wins in the test set using the model equation and calculate their errors.
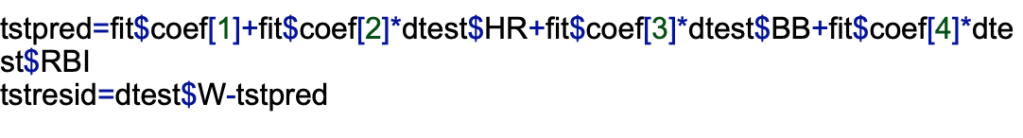
Now that I have calculated the errors for the test set, I can draw histograms of the errors in both of the sets and look at the average size of the errors for each test.
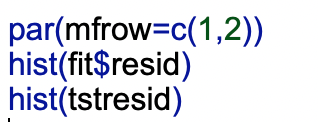
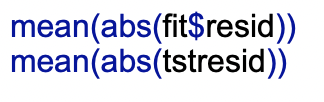
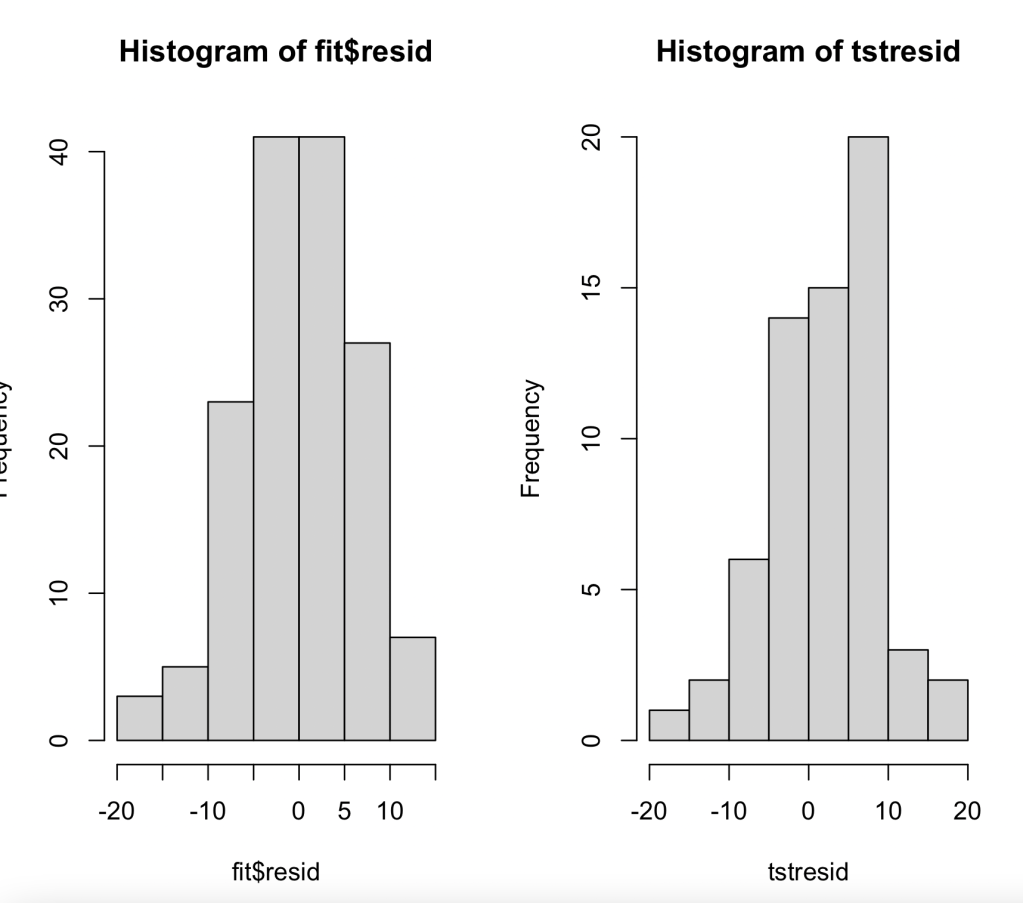

These two histograms do not differ much. They are both centered around 0 with the tstresid histogram being skewed a little more towards 10. Also the means are pretty similar so this means the model is stable. When trying to predict wins, the model is usually off by about 5. Also the histogram shows that wins can be off by 10 to 20 wins. This shows that while stable, the model is very inaccurate. It is very important that a model is both stable and accurate.
