
Using my MLB data set, I decided to make a decision tree to compare performance results with past models. I chose the regression tree format over the classification tree because the variable i’ve been trying to predict (team wins) is continuous and not binary. Firstly, I read in the data and used a function called “library(rpart)”, which is the decision tree function, to set up my linear regression model.

Next, I split the data into training and test sets to assist in making in-sample and out-sample predictions.

After splitting the data, I made my linear regression model using that new “rpart” option. When choosing which variables to use in my model, I echoed my previous model in previous blog posts using batting average, home runs, and runs batted in to predict team wins in binary predictions.
This code above then printed out my decision tree which is down bellow.
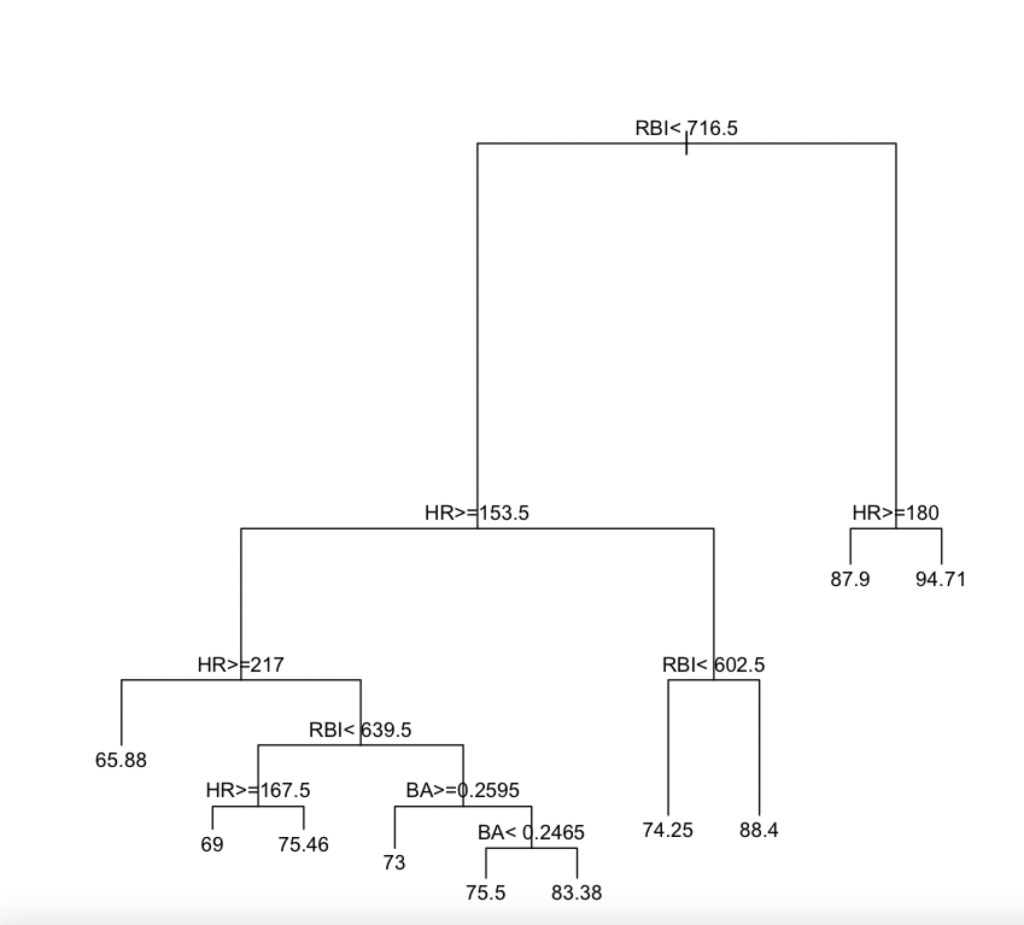
Now I will create in-sample predictions using training data and out-sample predictions using test data.


What the output above is showing is the predicted wins for each observations. For example, with in-sample data the model predicts 87.9 wins at the 49th observation. For out-sample data, the model predicts 69 wins for the 10th observation. For the in-sample data you can see that the first two observations give the same prediction. For the out-sample data the second two observations also have the same prediction.

These coefficients create the linear model used to predict wins of:
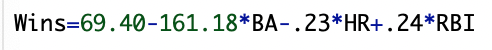
Now I will measure the average absolute error using both the in-sample and out-sample data.
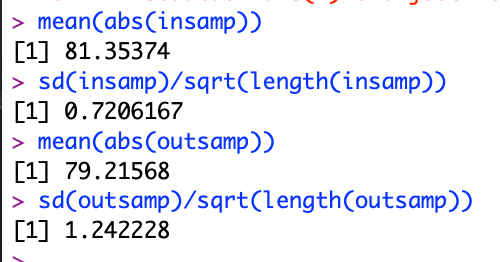
For linear regression, the average absolute error was 81.35 wins. That is HUGE because there are only 162 games played in a baseball season. The same can also be said about the test data (out-sample). It shows an average error of 79.2 games. Having the out of sample error be slightly smaller than the in-sample data means that it does as well as it would on in-sample data.
However, when we compare the error to that found in blog post 12, we see that this decision tree error is way off.
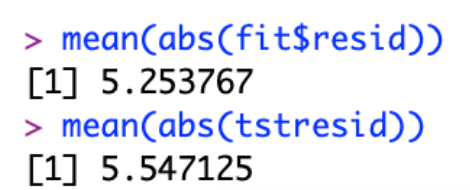
Having such high errors (81.35 and 79.21 ) shows that this decision tree model is HIGHLY inaccurate. Being off by around 80 wins is incredibly horrifying. The model is also unstable because a small change in input and data can yield highly different results.
